Data Enginering Stock Project
Final project for the Data Engineering Nanodegree program at Udacity. This end-to-end data engineering project demonstrates the implementation of a complete data pipeline for stock market data analysis and processing, showcasing the skills learned throughout the program.
Problem
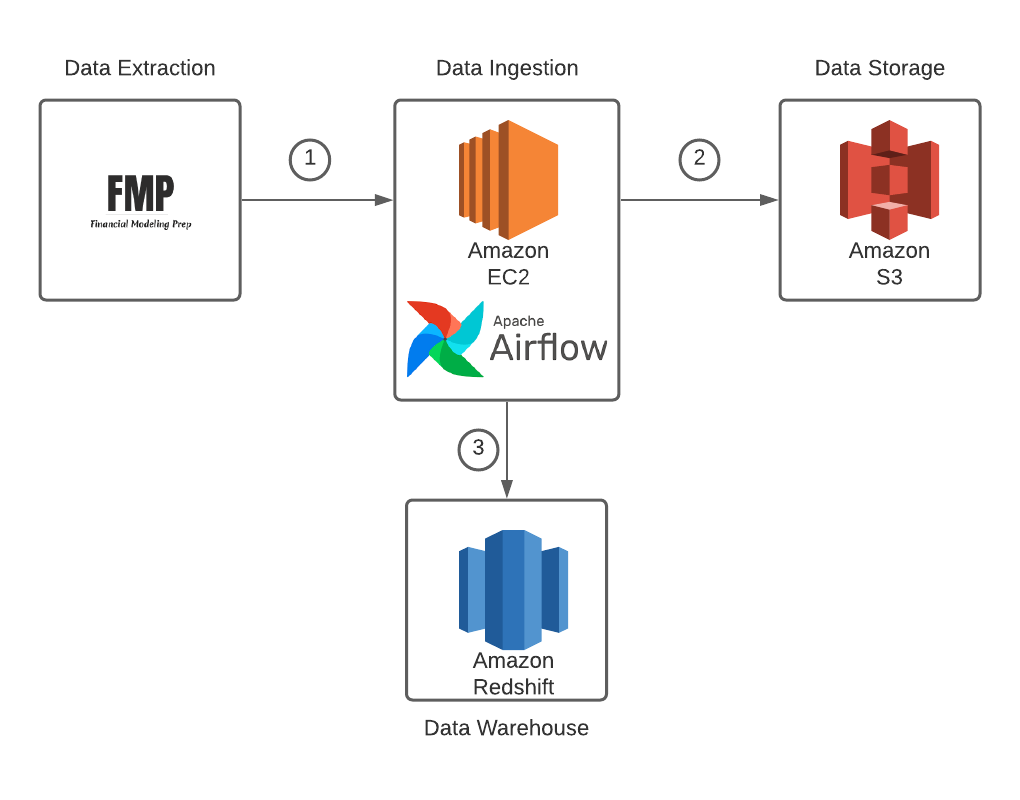
As a final project, I built a scalable and automated data platform to analyze historical and real-time stock market data from multiple sources. The previous process relied on manual CSV uploads and lacked reliability, making time-series analysis slow and error-prone.
Solution
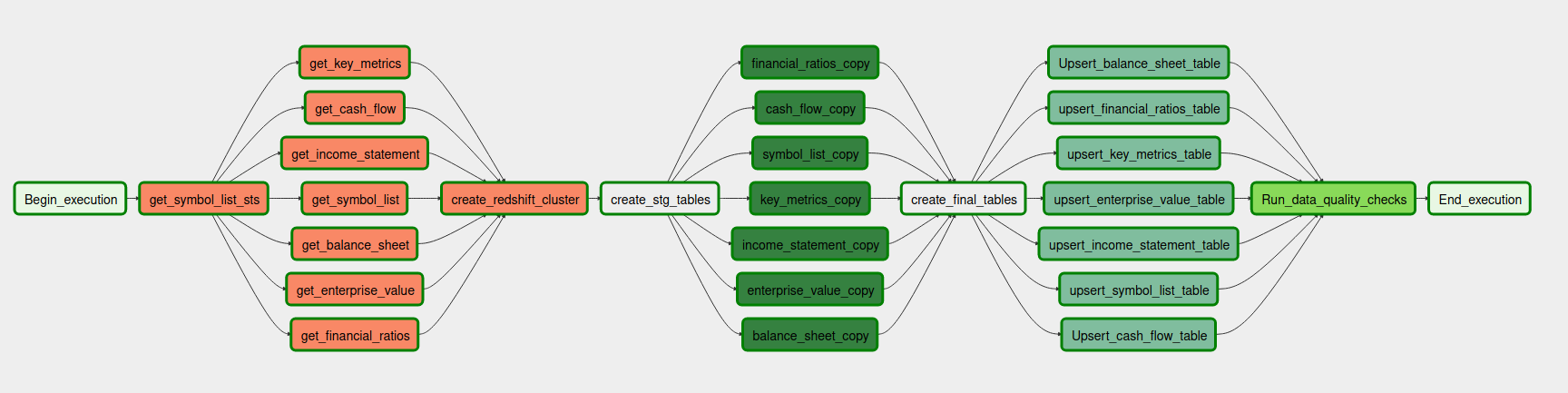
Developed a robust ETL pipeline that ingests stock data from external APIs, stores it in S3 as a data lake, and transforms it using Apache Spark before loading into Amazon Redshift for analytical queries. The workflow was automated and orchestrated to ensure reproducibility and maintainability.
Impact
Enabled analysts to query and visualize stock performance trends efficiently, reducing manual data preparation time by over 80%. Provided a scalable architecture that can be extended to include real-time streaming and predictive analytics.
Tech Stack Used
Key Challenges & Learnings
- Managing schema consistency between raw, staging, and analytics layers
- Optimizing Spark transformations to handle large stock datasets efficiently
- Ensuring AWS resources and IAM roles were properly configured for security and automation
- Gained practical experience designing and deploying an end-to-end data pipeline on AWS
- Improved understanding of data lake and data warehouse integration patterns
- Learned best practices for structuring ETL jobs using Spark and managing cloud resources programmatically
Screenshots